[ 컴퓨터 구조 ] 22. Cache performance
Cache 의 performance를 올리기 위해서는
어떤 locality의 장점을 가져오는 게 좋을까?
1) Temporal - 가져온 데이터 블럭, 그걸 또 이용할 거. : 1word
2) Spatial - 가져온 거 근처에 있는 것들도 가져와서 걔네도 쓸 거
그럼 한 블럭에 여러 word를 가져와야함


왼쪽은 1 word를 가져왔을 때, 즉 data에 하나의 word만 담겨서 들어올 때의 모습이고
오른쪽은 4 words를 가져왔을 때의 모습이다.
64KB 캐쉬 메모리가 4words blocks을 가져옴
= 2 ^16 bytes
= 2 ^14 words ( 1 word = 4 bytes )
= 2 ^12 blocks ( 1 block = 4 words )
→ 하나의 block에 4개의 word를 담아오기 때문에.
+ 그 4개의 word 중 어느 것을 reference하는지 나타내는 block offset bits도 필요하다.
Multiple Word Direct Mapped Cache의 장단점
● 장점 : Spatial Locality 의 장점을 취할 수 있다.
1) 1 block에 여러 words를 가질 수 있음
2) 같은 block은 같은 tag와 valid bit를 공유한다. ( 한 tag칸에 4words가 있는 거 )
● 단점 : 한 번 Miss나면 4 words를 갖고와야해서 좀 시간이 더 걸린다.
Performance 측면 분석
● Miss penalty :
[ Mem -> cache 로 필요한 메모리 부르는 시간 ] + [ 가져온 Block을 processor로 보내는 시간 ]
참고로 hit time << miss penalty 임.
당연함, hit이면 슥 가져오면 되고, miss면 메모리가고 캐시로 오고 processor...시간 많이 걸림
ex) 진열대에 상품이 있으면 그냥 그거 가져가면 되고, 없으면 창고에서 찾아와야함.
● Execution time
= ( execution clock cycles + stall clock cycles ) * cycle time
= ( 실행하는 데 걸리는 CLK 개수 + 멈춰야 하는 CLK 개수 ) * 한 CLK당 걸리는 시간
* [ 참고 ] 멈춰야하는 CLK = Inst 개수 * miss 날 확률 * miss났을 때 대처하는 데에 걸리는 시간
● Performance 올리는 법
: 1) Miss 확률을 줄이든지
2) Miss 페널티를 줄이든지
[ 나올 수 있는 질문 ] : miss를 안 내려면, block size를 키우면 되지않나?
- Block 사이즈를 키우면 Miss가 날 확률은 줄어든다.
하지만, 그러면 생기는 문제는 다음과 같다.
1) Cache에 들어갈 수 있는 Block의 개수가 줄어든다.
→ Block 의 크기가 크므로, 칸이 하나만 들어가도 다 찰 수가 있다.
2) Spatial locality가 줄어든다.
→ 주변에 앞으로 사용할 애들도 같이 데려오는 게 Spatial locality인데
그냥 다 데려오면 그냥 메모리를 채로 가져오는 거랑 다를 게 없다.
3) Miss가 나면 그 큰 size를 다시 mem에서 채워서 가져와야해서 시간이 엄청 걸린다.
Cache 구조의 종류

이렇게 3가지가 있다.
a. One word wide memory
- Memory 와 Cache사이에 1 word 전용 BUS가 있어서, 데이터가 오갈 수 있다.
b. Wide word wide memory
- Memory 와 Cache사이에 많은 word 전용 BUS가 있어서, 데이터가 한 번에 많이 오갈 수 있다.
추가로, Cach에 많은 데이터가 있기에, CPU로 가기 위해서는 MUX를 이용함.
- Memory 와 Bus를 widen하는 건 비용이 많이 든다.
c. Interleaved memory organization
- Bus는 1word가 오갈 수 있는 BUS이지만, Memory를 bank로 나누어 놔서 각 bank에서
@번 index 데이터 1word씩을 Cache에 가져온다.
(대신 보내는 건 1word BUS이므로, 하나씩 보낼 수 있다.)

문제)
address를 보내는데 1cycle
1 word data를 읽는데 15cycles
1 word data를 보내는데 1cycle
각 구조에서 1 block = 4 words 를 [ Mem → Cache ] 하는 데에 걸리는 시간은?
a) 1 + (15 *4) + (1*4)
= 1 + 60 + 4 = 65
b) 1 + 15 + 1 = 17
- 4word를 한 번에 오게 할 정도로 통로가 크다
c) 1 + 15 + (1*4) = 20
- 읽는 건 각각의 bank 로 가서 하니까 동시에 할 수 있음
- 보내는 건 0번부터 4번 순서로 보냄 ←1word BUS라서!!
Placements / Replacements
Placement 방법에는 3가지 방법이 있다.
1) Direct : Tag로 자신에게 맞는 칸에 mapped된다
태그는 주로 자신의 Address 를 나눈 나머지가 된다.

2) Fully associative : 빈칸이 있으면 그냥 아무렇게나 들어간다.
특징 : 아무 곳에나 저장 가능
= 정보 찾으려면 오래 걸림
> parallel하게 동시에 [ 찾으려는 데이터의 tag ]와 [ 주소를 나타내는 tag ] 여러 개 비교할 수 있도록 만들어야 한다!


3) Set associative : 위 2개가 섞인 느낌이다. Set는 태그로 들어가고, 그 안에서는 맘대로 들어감
ex) 도서관: 전전은 1열람실, 생명은 2열람실로 가고, 그 안에서는 걍 니네 맘대로 앉아라
아래 사진에서는 가운데가 Set associative

태그 2개를 하나의 set로 취급한다.
따라서, 8칸이 아닌 4개의 칸으로 생각하며,그걸 태그로 취급한다.
● 작동 방식 :
1) 가야하는 set 태그에 들어간다.
ex) 12 mod 4 = 0 -> 0번 set에 들어간다.
2) 0번 set에서 아무 곳이나 들어간다.
위에 나온 placement들은 모두 아래와 같이 표현할 수 있다.

Associative set 특징
● 장점 : Associative set의 개수가 늘어나면 miss날 확률이 줄어든다.
● 단점 : hit인지 확인하는 데 오래걸림.
ex) tag로 들어가서 다 찾아보고, 그 다음 tag에서 다 찾아보고...
Replacement
miss가 난 경우에 Fully나 set associative cache에서는 어떻게 해야할까 에 대한 대답
배경 : Direct mapped에서는 어떤 데이터가 들어갈 때, 빠져야 하는 애는 [ 같은 tag ] 에 있는 data인데
fully나 set associative이고, data가 꽉 차있고 miss가 나서 새로 cache에 데이터를 넣을 때는
정해진 게 없어서 어떻게 넣어야 하는지 고민임 (*set associative는 set 안에서 말하는 거임)
Replacement 방법에는 4가지 방법이 있다.
1) 랜덤 : 새로운 애 들어와야 하니까 아무나 나가
2) 선입선출 ( First In, First Out )
- 가장 오래동안 있었던 애를 내보냄
- 이를 위해서는 언제 왔는지 알기 위한 Time Stamp 기능이 필요함
- Queue로 구현 가능
*문제점 : 걔가 앞으로 가장 많이 쓰일 데이터라면??
3) Least Recently Used (LRU)
- 가장 최근에 사용하지 않은 것 = 지금 기준 제일 옛날에 "사용" 한 것을 내보냄
- 쓰일 때마다 Time Stamp 필요하다 = Overhead가 심하다.
FIFO와 공통점 : Time Stamp를 참고하여 내보낸다
차이점 : Time Stamp가 찍히는 시점이 다르다 ( 들어왔을 때 vs 사용될 때 )
4) Least Frequently Used (LFU)
- 가장 적게 쓰인(= reference된 ) 것
Reference될 때마다 count를 하고, Miss이고 데이터가 다 찼을 때 count값이 가장 적은 데이터를 내보냄
빈틈 : 들어온지 얼마 안 된 데이터는 상대적으로 count가 적을 수 밖에 없어서 얘네가 쫓겨날 수도 있음


... 따라서 가장 이상적인 Replacement 알고리즘은
앞으로 가장 쓰이지 않을 Data에 replace하는 것이 가장 이상적이다.
= 주로! Least Recently Used가 성능이 좋다고 알려짐
예제)

데이터에 0 > 8 > 0 > 6 > 8 이렇게 넣는다고 해보자 / 그리고 알고리즘은 LRU (가장 옛날에 쓰인 거를 뺌)
1) direct-mapped 일 때
> address를 cache 칸 개수로 나누어 나머지에 따라 index=tag 를 부여한다.
> 0 → 0번 칸으로 들어감 (miss)
> 8 → 0번 칸으로 감 (miss and replacement)
> 0 → 0번 칸으로 감 (miss and replacement)
> 6 → 2번 칸으로 감 (miss)
> 8 → 0번 칸으로 감 (miss and replacement)
2) 2 way set associative 일 때
> address를 cache set 개수로 나누어 나머지에 따라 index=tag 를 부여한다.
> 0 → 0번 set / 1번 칸으로 들어감 (miss)
> 8 → 0번 set / 2번 칸으로 들어감 (miss)
> 0 HIT!!
> 6 → 0번 set / 2번 칸으로 들어감 (miss and replacement) , 이유 : LRU이므로
> 8 → 0번 set / 1번 칸으로 들어감 (miss and replacement)
3) fully associative 일 때
> 0 → 0번 칸에 들어감 MISS
> 8 → 1번 칸에 들어감 MISS
> 0 → 0번 칸에 있음 HIT
> 6 → 2번 칸에 들어감 MISS
> 8 → 1번 칸에 있음 HIT
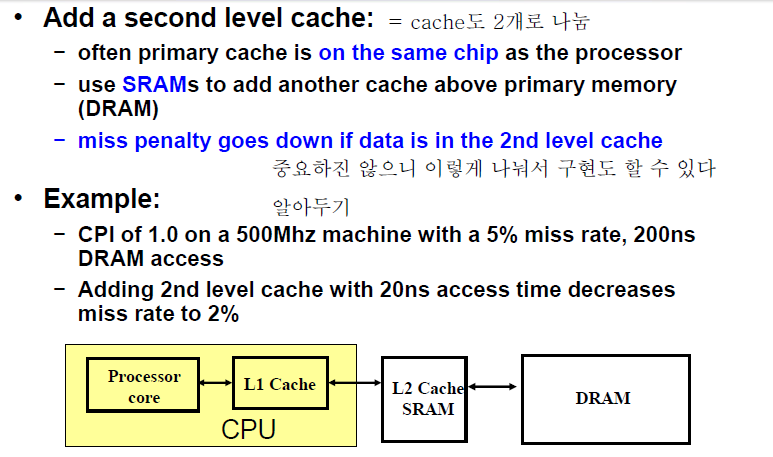
Cache를 두 단계로 나눌 수도 있다
CPU 내부에 / 외부에
단, 내부에 있는 게 더 작고 빠름
(출처)
한동대학교 용환기교수님 - 컴퓨터구조