

오래 못 할 짓 하지 않기
[ 데이터베이스 ] 2. Relational Database 본문
Relation을 알기 위해 알아야 하는 개념
● Set
: 서로 다른 elements를 가지는 집합
순서는 중요X
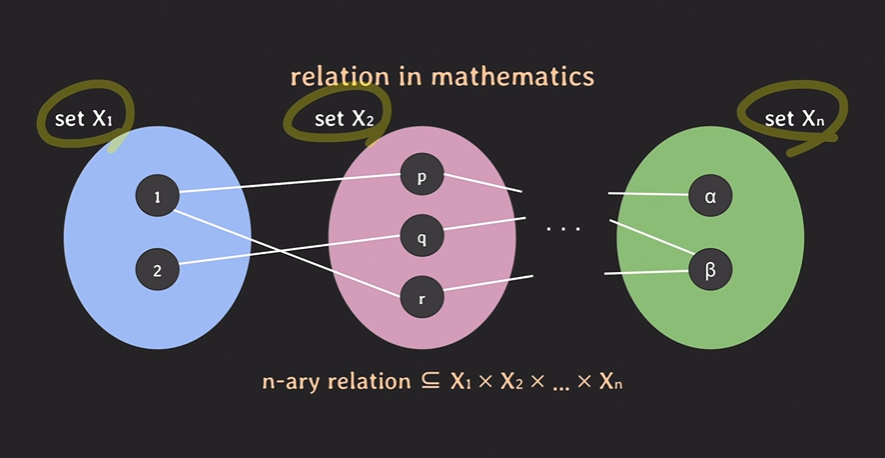
Relation의 형태는 이와 같다.
위와 같은 List를 [ Tuple = n개의 element로 이루어진 list ] 이라고 부를 수 있다.
Relational data model
여기에서는 Set = Domain
ex) 학생 정보로 relation을 만들어보자
● student_ids : 학번 집합
● student_names : 학생 이름 집합
● university_grades : 학년 집합
● major_name : 전공 집합
● phone_nums : 핸트폰 번호 집합

이렇게 만들었다.
근데 이 학생의 비상연락망도 추가하려고 하니
동일한 Domain이 같은 Relation 안에서 두 번 사용되지만, 목적과 역할이 다르다.
이를 표시하기 위해 Attribute를 표시한다.
Attribute는 Domain들이 그 Relation에서 어떤 역할을 하는지 나타낸다.
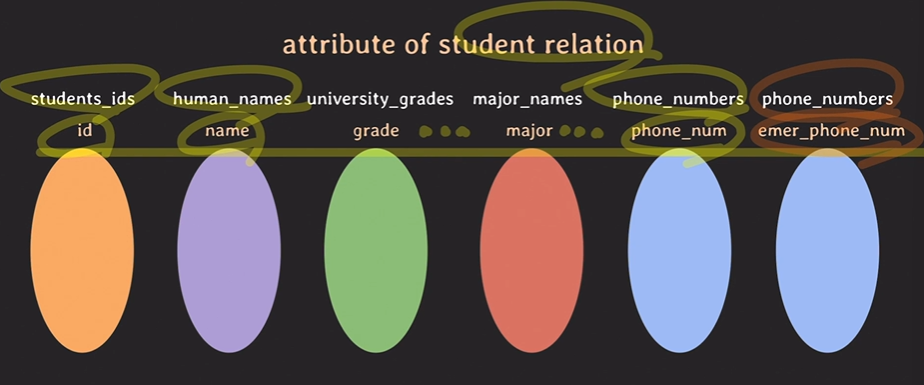
표시를 한다면 다음과 같다.
이 안에 값들이 들어갈 것이고, 그 값들마다 데이터로 사용되는 Tuple들이 있을 것이다.
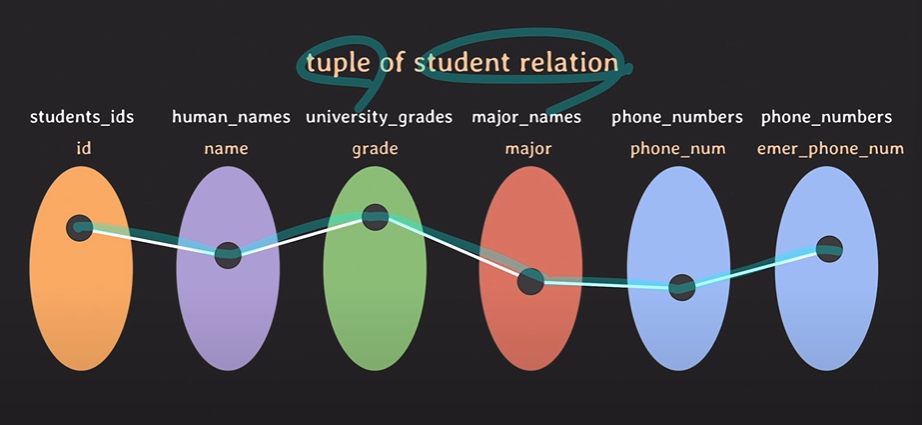
이러한 관계를 가장 잘 표현하기 좋은 것은 Table이다.

짚고 가야하는 개념들
Domain : Set of atomic values = 더 이상 나눠지지 않는 값의 집합
Attribute : Domain이 Relation에서 맡은 역할
Tuple : 각 attribute의 값으로 이루어진 리스트 / 일부 값은 NULL일 수 있다.
Relation Schema
- Relation 이름 + Attributes 리스트로 표기
ex) STUDENT ( id, name,grade,major )
- Attribute와 관련된 Contraints도 포함
Degree of a relation : relation schema에서 attributes의 수
ex) STUDENT ( id, name,grade,major ) → Degree : 4
Relational Database Schema
relation scemas set + integrity constraints set
Relation 의 특징
1) 중복된 Tuple은 가질 수 없다.

2) Tuple을 식별하기 위해 Unique한 값을 attribute의 key로 설정한다.

3) Tuple의 순서는 별 의미없다. / 하나의 Tuple에서 attribute의 순서는 중요하지 않다.
4) 하나의 Relation에서 Attribute의 이름은 중복되면 안된다.
5) Attribute는 atomic해야한다. = 더 이상 나눠지지 않는 걸 타겟으로 만들어야 한다.
= 하나의 attribute가 여러 값을 가지면 안 된다. (Composite or Multivalued X )

NULL
의미 : 값이 업데이트 되지 않았거나
값을 입력하지 않았거나
KEY
● Superkey
: Relation에서 Tuple을 Unique하게 식별할 수 있는 Attributes set
→ Select 쿼리를 했을 때 한 놈만 나오게 하는 Attributes set
STUDENT(id,name,class,phone_num,birth_date,team)에서
Relation에서는 중복되는 tuple을 허용하지 않기 떄문에
전체 Attribute set은 항상 Superkey가 될 수 있다.
또 위와 같은 Relation에서는 { id, name } 이 superkey가 될 수 있고
{name , class, birth_date} ...등등 될 수 있는 set은 아주 많다.
● Candidate key
: 어느 한 attribute라도 제거하면 Unique하게 식별할 수 없는 Super key
→ Select 쿼리에서 하나의 Attribute만 없애면 여러 놈이 나오는 것
ex) PLAYER ( id, name, team_id, back_num,birth_date)에서의 candidate key는
{id}, {team_id,back_num}
→ 두 번째 set을 보면,
team_id만 있을 경우 : 같은 팀으로 검색하면 나오는 애들이 엄청나게 많을 것
back_num만 있을 경우 : 다른 팀끼리는 등번호가 같은 경우가 많다.
ex) back_num = 7 인 걸 찾으려면 , 한국 7번, 일본 7번 , 브라질 7번 다 나옴
한 놈만 나오게 하려면 팀 id를 함께 넣어야 함
● Primary key
: Relation에서 Tuple을 Unique하게 식별하기 위해 선택된 Candidate key
ex) PLAYER ( id, name, team_id, back_num,birth_date)에서의 primary key는
{id}, {team_id,back_num}
Tip : Attribute가 가장 적은 set으로 하는 게 좋음
그래서 웬만하면 Id로 하는 거임
● Unique key
: Primary key가 아닌 candidate keys
= Altenate key
ex) PLAYER ( id, name, team_id, back_num,birth_date)에서의 Unique key는
{team_id,back_num}
● Foreign key
: 다른 Relation의 Primary Key를 참조하는 Attributes set

위 경우에는 [ PLAYER relation에 있는 team_id ] 가 [ TEAM relation에 있는 id ]를 참조할 수 있다.
따라서, team_id로 접근하여 TEAM relation에 있는 정보를 참조할 수 있음.
Constraints
Relational DB의 Relation들이 지켜줘야 하는 제약 사항
● Implicit Constrains
: Relational data model 자체가 가지는 Constrains
ex)
★ Relation은 중복되는 tuple을 가질 수 없다.
★ Relation 내에서는 같은 이름의 attribute를 가질 수 없다.
● Schema-based Constrains
주로 DDL을 통해 shema에 직접 명시할 수 있는 Constrains
● Explicit constraints
- Domian Constraints
: Attribute의 value는 해당 attribute의 domain 에 속한 value여야 한다.

2. Key Constraints
:서로 다른 tuples은 같은 value의 key를 가질 수 없다.

3. NULL value Constraints
: Attribute 가 NOT NULL로 명시되었다면 NULL값을 가질 수 없음
4. Entitiy integrity constraint
: Primary key는 value에 NULL을 가질 수 없다.
5. Referential integrity Constraints
: Foreign key와 Primary key와 도메인이 같아야하고
Primary key에 없는 Values를 Foreign key가 Value로 가질 수 없다.

(참고)
유튜브 쉬운코드
'3학년 1학기 > 데이터베이스(DB)' 카테고리의 다른 글
| [ 데이터베이스 ] 6. NULL / 3 valued logic (0) | 2023.12.31 |
|---|---|
| [ 데이터베이스 ] 5. Subquery (0) | 2023.12.31 |
| [ 데이터베이스 ] 4. SQL 활용 ( 추가/수정/삭제 ) (0) | 2023.12.30 |
| [ 데이터베이스 ] 3. SQL (0) | 2023.12.28 |
| [ 데이터베이스 ] 1. 기본 개념들 ( DB , DBMS ) (0) | 2023.12.26 |



