
오래 못 할 짓 하지 않기
[ 데이터 과학 ] 7. Tidiness of Data 본문
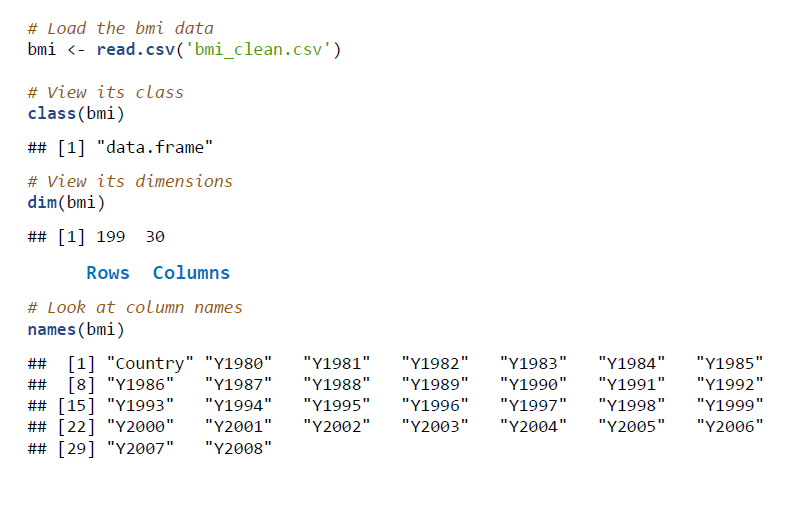
- class : 해당 변수가 어떤 타입인지
- dim : 몇 개의 Column과 Row가 있는지
- names : Column들의 이름
- str : 위 내용들을 다 알려줌
- summary : 각 Column에 대해 평균,최대,최소 등을 알려준다.
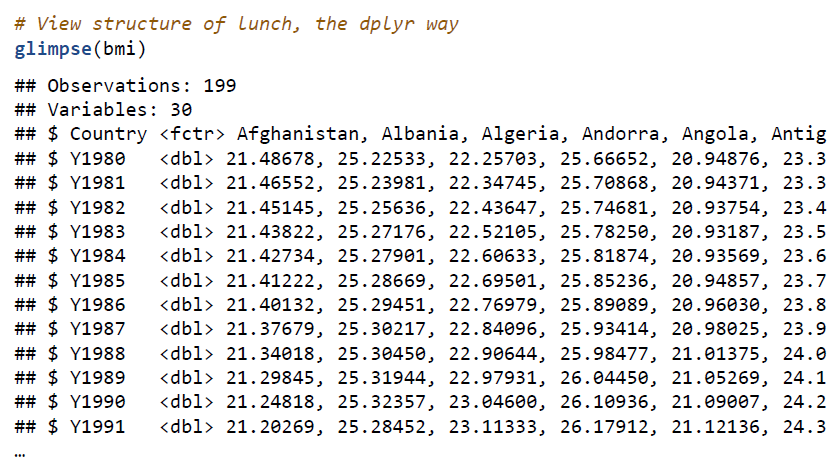
- glimpse : str 명령어와 같은데, 얘는 화면 크기가 허용하는 한 다 보여주려고 함
- str : 대충 자기가 보여주다가 어느 정도 된다 싶으면 끊어버림
Visualization
hist( 변수명 )
: 하나의 데이터에 대한 흐름을 보고 싶다.

plot( x = 변수1, y= 변수2 )
: 두 개의 변수에 대해 plot을 보여줌

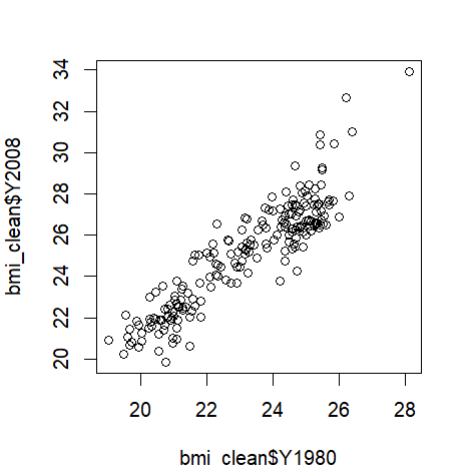
look at some dirty data
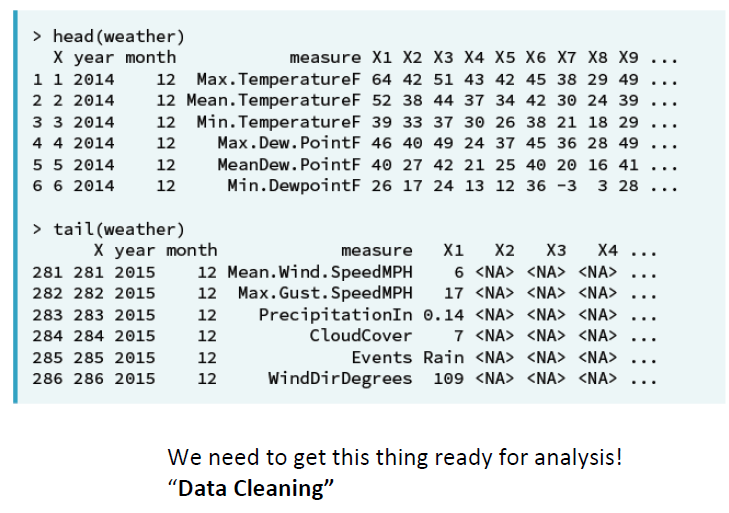
분석하기 좋은 데이터는 head 쪽에 있다.
밑에는 찌꺼기들이 많음.
Tidy Data
- Value가 Attribute인 경우
- Attribute가 Value인 경우
- 한 Attribute에 2개의 Value가 있는 경우
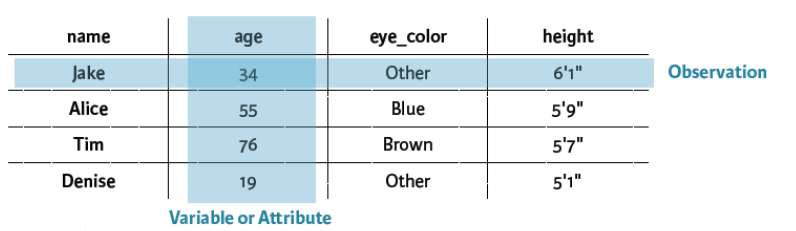
행 = Observation
열 = Attribute or Variable
인 상태인 데이터들이 가장 Clean하다고 한다.

이렇게 같은 value로 들어가야 하는 것이 Attribute로 되어 있는 것은 깨끗하다고 하지 못한다.
아래와 같이 깨끗하게 만들 수 있다.

반대인 경우도 있다.
Variable이어야 하는 것이 Value인 경우도 있다
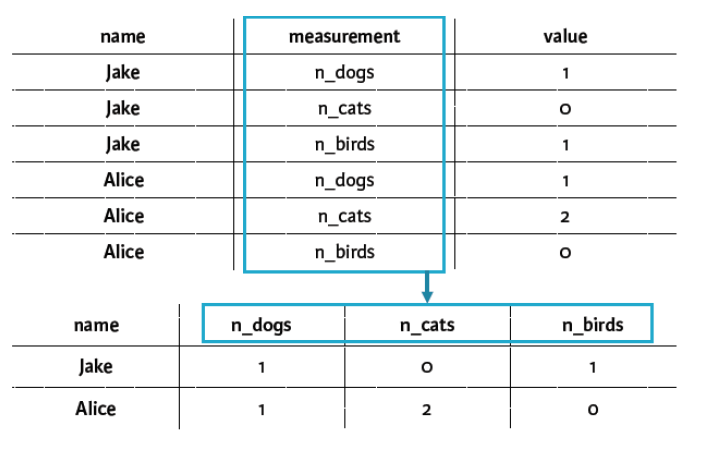
하나의 Attribute에서 2개의 값을 받을 때 Tidy하지 않다.
두 개로 나눠주자

크게 공통점이 없거나 주제가 다른 내용이 한 테이블에 있을 때
이를 나눠야 한다.

해결 방법
value로 들어가야 하는 것이 Attribute로 되어 있는 것은 깨끗하다고 하지 못한다.
아래와 같은 방법으로 바꿀 수 있다.

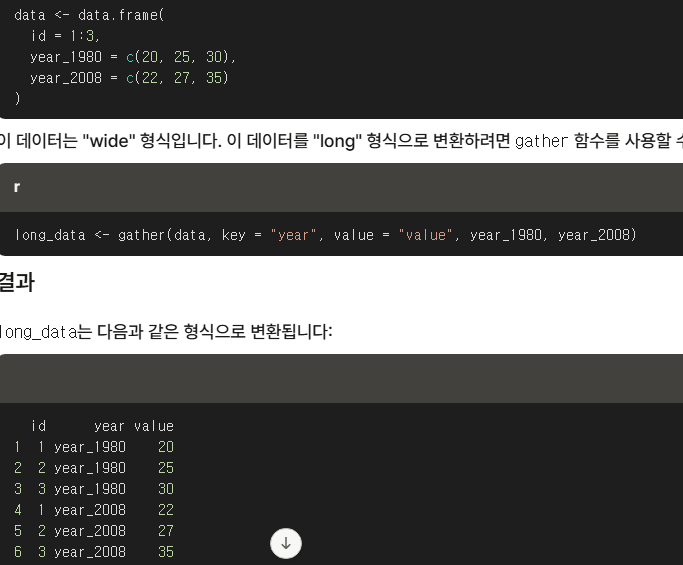
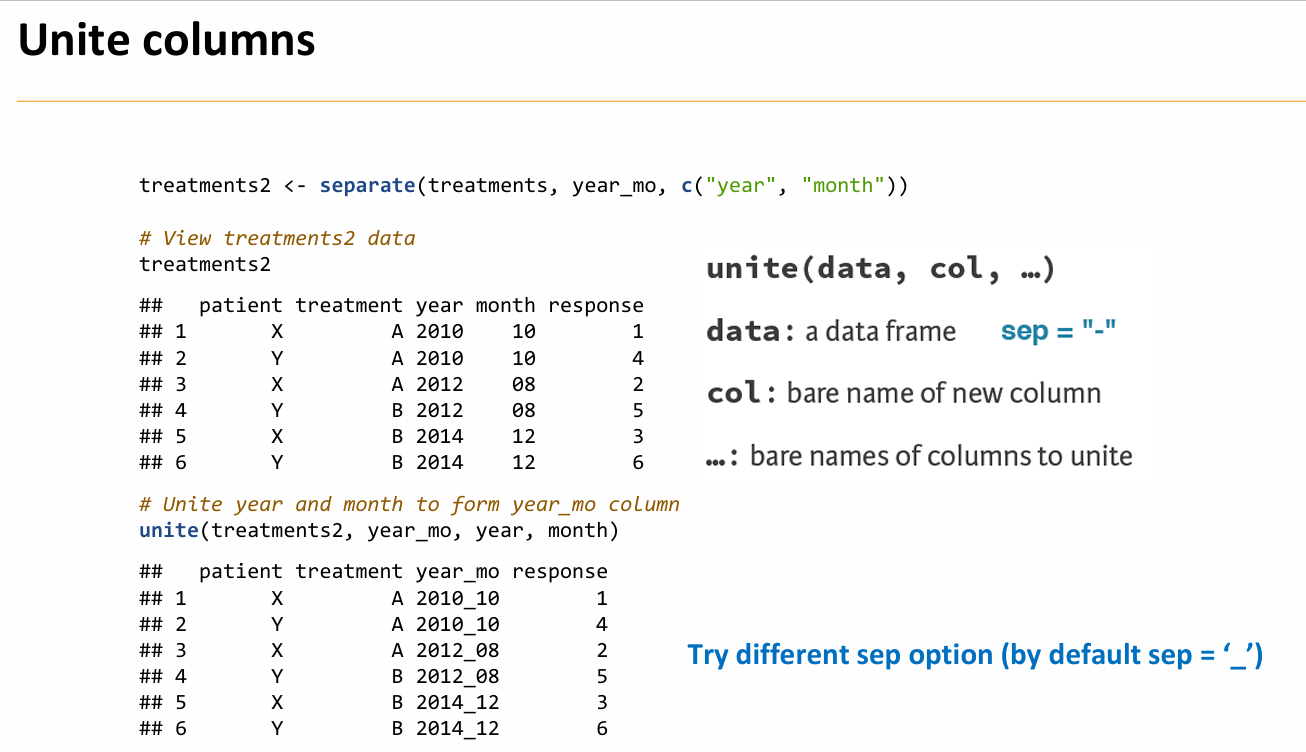
col을 기준으로 합쳐주는 걸 생각하자.
마지막 인자는 합치는 기준이 되어준다.
gather(데이터 , 첫 데이터 , 그에 매칭되는 값 , 매칭 기준 )

반대로도 하는 걸 보자.
spread를 사용하면 된다.

spread( 데이터 , 첫 데이터 , 그에 매칭되는 값 )
Separate랑 Unite는 좀 직관적이다.
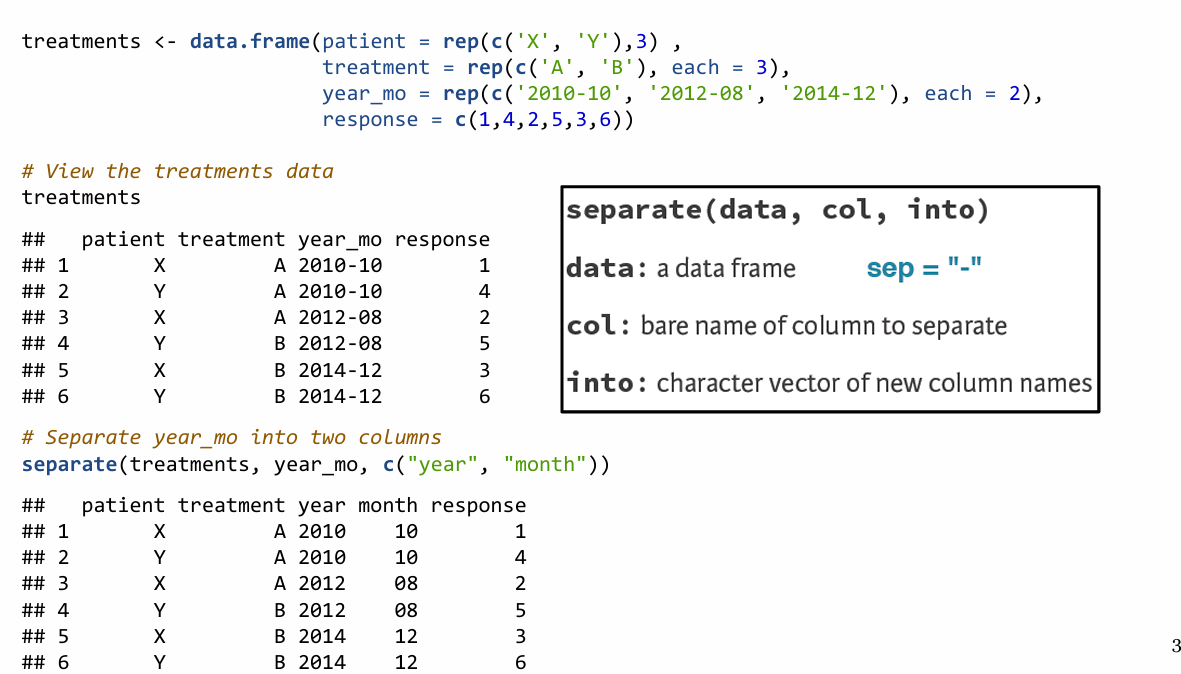
문제 풀어보자! gather / spread가 약간 어렵다.
(자료 출처)
한동대학교 김현정교수님 - 데이터과학
'4학년 > 데이터 과학 ( Data Science )' 카테고리의 다른 글
| [ 데이터 과학 ] 9. Missing Value / Outlier (0) | 2025.04.03 |
|---|---|
| [ 데이터 과학 ] 8. Type Conversion (0) | 2025.03.31 |
| [ 데이터 과학 ] 6. R 언어 기능4 (0) | 2025.03.24 |
| [ 데이터 과학 ] 5. R 언어 기능3 (0) | 2025.03.20 |
| [ 데이터 과학 ] 4. R 언어 기능2 (0) | 2025.03.17 |



