

오래 못 할 짓 하지 않기
[ 데이터베이스 ] 8. 데이터 조회 - Group/ Aggregate / Order 본문
Order by
- 조회 결과를 특정 Attribute(들) 기준으로 정렬
- 오름차순 ACS (Defualt)
- 내림차순 DESC
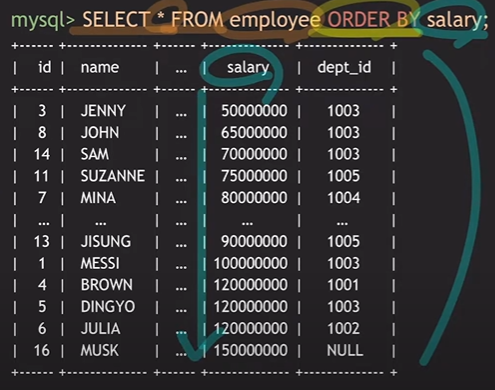
예) 연봉 기준으로 모든 직원들을 정렬하려면?
오름차순 : Select * From employee ORDER BY salary;
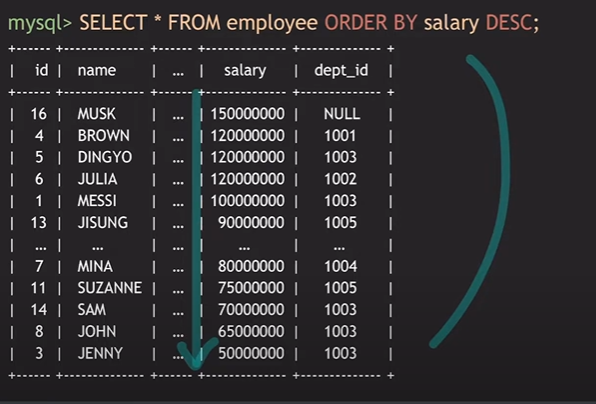
내림차순 : Select * From employee ORDER BY salary DESC;
예2 ) 직원들을 부서별로 오름차순 정렬하고, 같은 부서 내에서는 연봉 기준으로 내림차순으로 정렬한다면?
Select * From employee ORDER BY dept_id ASC, salary DESC;
▶ 여러 Attribute 가 올 때 우선순위는 앞에 명시된 Attribute 차례로 정렬된다.
Aggregate function
: 여러 Tuple들의 정보를 요약해서 하나의 값으로 추출
ex) COUNT, SUM, MAX, MIN, AVG
▶ AVG(salary) , MAX(birth_date)
특징) NULL은 카운트 안 함
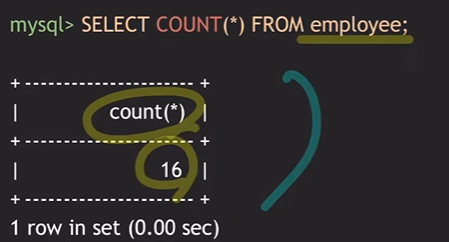
예) 직원 수를 찾아내라
SELECT COUNT(*) FROM EMPLOYEE;
→ count 뒤에 (*)가 오면 tuple의 수를 말한다.
이렇게 했을 땐 16이 나오고
SELECT COUNT(dept_id) FROM EMPLOYEE;
이렇게 했을 땐 14가 나온다. 그 이유는?
→ dept_id 값이 null인 데이터가 2개 있다는 뜻

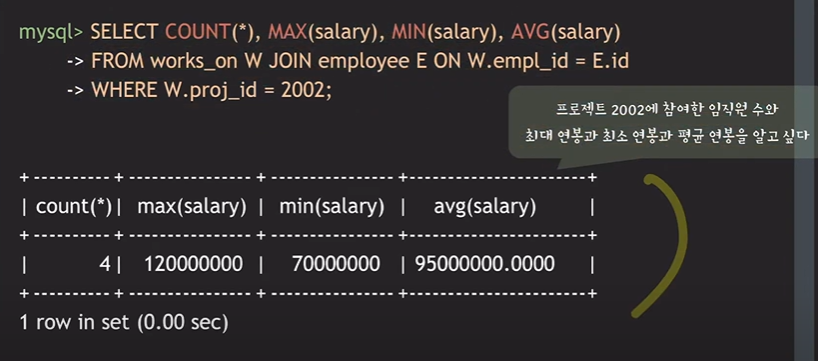
예) 프로젝트 2002에 참여한 직원수 , 최대 연봉 , 최소 연봉 , 평균 연봉을 알고 싶다.
(내가 쓴 답)
Select COUNT(*), MAX(salary), MIN(salary), AVG(salary)
From employee
where proj_id = 2002;
Select COUNT(*), MAX(salary), MIN(salary), AVG(salary)
From works_on W Join employee E on W.empl_id=E.id
Where proj_id=2002;
Group by
특정 컬럼을 그룹화한다.
즉 하나의 컬럼에 대한 여러 정보들을 나타낼 때 사용함
[ 정확한 설명 ]
특정 Attribute(s) 기준으로 그룹을 나누어, 그룹별로 aggregate function을 적용하고 싶을 때 사용
※ Grouping attribute에 NULL값이 있을 때는 NULL값을 가지는 tuple끼리 묶인다.
예2) 각 프로젝트에 참여한 직원수 , 최대 연봉 , 최소 연봉 , 평균 연봉을 알고 싶다.
Select COUNT(*), MAX(salary), MIN(salary), AVG(salary)
From works_on W Join employee E on W.empl_id=E.id
Where proj_id=2002;
위에 코드는 2002 프로젝트에 대한 정보들이다.
그럼 각 프로젝트에 대한 정보들을 출력을 하려고 하면 Group by를 사용하면 된다.
Select W.proj_id, COUNT(*), MAX(salary), MIN(salary), AVG(salary)
From works_on W Join employee E on W.empl_id=E.id
GROUP BY W.proj_id;
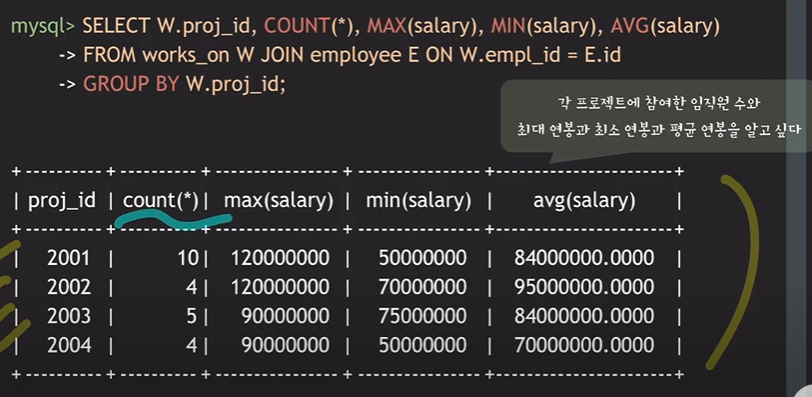
[ 풀이 ]
1) SELECT에 W.proj_id를 넣어주어야, 결과에 어떤 프로젝트에 대한 결과인지 알 수 있음
2) 마지막에 WHERE 이 아니라 GROUP BY W.proj_id를 만들어 어떤 항목을 기준으로 그룹을 만들지 정해두었다.
Having
Group by + Condition 이라고 생각하면 됨
Group by의 결과를 바탕으로 필터링을 하는 역할
예1) 프로젝트에 참여한 인원이 7명 이상인 프로젝트에 대해서
각 프로젝트에 참여한 직원수 , 최대 연봉 , 최소 연봉 , 평균 연봉을 알고 싶다.
Select W.proj_id, COUNT(*), MAX(salary), MIN(salary), AVG(salary)
From works_on W Join employee E on W.empl_id=E.id
GROUP BY W.proj_id
Having Count(*) >= 7;
예제 파티
문제 1) 각 부서별 인원수가 많은 순으로 정렬해서 알고싶다.
(출력은 dept_id랑,인원수만 출력하면 됨)
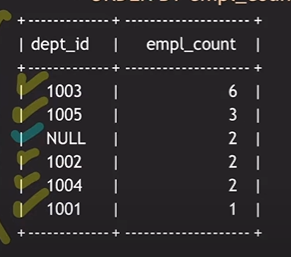
(내가 틀린 답)
Select * from employee Order by Count(*) DESC;
Select dept_id, COUNT(*) AS empl_count From employee
▶Group by dept_id
▶Order by empl_count DESC;
문제 2) 각 [ 부서 - 성별 ] set에 대해 인원수가 많은 순으로 정렬해서 알고싶다.
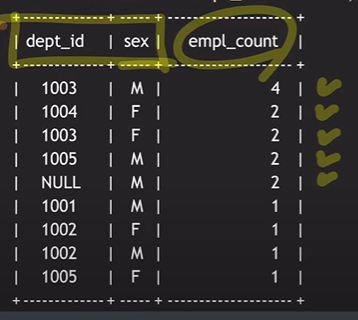
Select dept_id, sex, COUNT(*) AS empl_count From employee
▶Group by dept_id,sex
▶Order by empl_count DESC;
알게된 거 ) Group by 에 attribute가 여러 개 오면 attribute1, attribute2 로 만들 수 있는 set들을 만들어서 수행한다.
문제 3) 회사 전체 평균 연봉 > 부서의 평균 연봉 이라면, 그 부서의 평균 연봉을 알아내라
Select dept_id,AVG(salary) from employee
▶ GROUP BY dept_id
▶ HAVING AVG(salary) < (
▶ SELECT AVG(salary) From employee
▶ ) ;
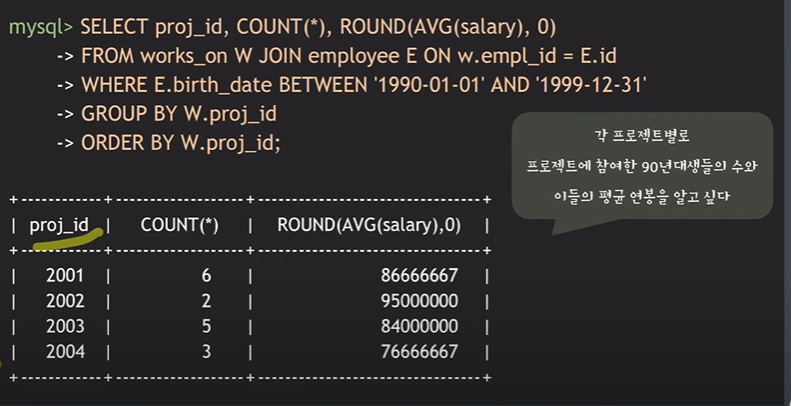
문제 4) 각 프로젝트별로 참여한 90년대생들의 수, 이들의 평균 연봉을 알아내라
(내가 발악하면서 만든 코드)
Select proj_id , Count(*) AS more_than_25, AVG(salary)
▶ From Works_on W Join Employee E On W.empl_id = E.id
▶ Group by proj_id
▶ Having COUNT(
▶ Select * from employee where birth_date < '2000-01-01' ;
▶ );
Select proj_id , Count(*), ROUND (AVG(salary) , 0 )
▶ From Works_on W Join Employee E On W.empl_id = E.id
▶ Where E.birth_date BETWEEN '1990-01-01' AND '1999-12-31'
▶ GROUP BY W.proj_id;
▶ ORDER BY W.proj_id; (필수는 아님)
ROUND : 소수점 생기면 반올림하는 거 ( 결과 , 소수점 얼마까지 )
BETWEEN : 조건 값 범위
추가 문제 ) 프로젝트에 참여 인원이 7명 이상인 프로젝트에 한정하여
각 프로젝트별로 참여한 90년대생들의 수, 이들의 평균 연봉을 알아내라
(내가 틀린 답)
▶ Select proj_id , Count(*) , ROUND(AVG(salary),0)
▶ From Works_on W Join Employee E On W.empl_id = E.id
▶ Where E.birth_date Between '1990-01-01' AND -1999-12-31'
▶ GROUP BY W.proj_id
▶ ORDER BY W.proj_id
▶ Having Count(*) < (
Select * from employee
)
그냥 대책없이 having 갖다 쓰려고 했음
▶ Select proj_id , Count(*) , ROUND(AVG(salary),0)
▶ From Works_on W Join Employee E On W.empl_id = E.id
▶ Where E.birth_date Between '1990-01-01' AND -1999-12-31'
▶ AND W.proj_id IN ( Select proj_id From works_on
▶ GROUP BY proj_id HAVING COUNT(*) >=7 )
▶ GROUP BY W.proj_id
▶ ORDER BY W.proj_id
(출처)
유튜브 쉬운코드
'3학년 1학기 > 데이터베이스(DB)' 카테고리의 다른 글
| [ 데이터베이스 ] 10. Stored procedure (0) | 2024.01.04 |
|---|---|
| [ 데이터베이스 ] 9. stored function (0) | 2024.01.04 |
| [ 데이터베이스 ] 7. Join (좀 어려움 ㅠ) (0) | 2024.01.02 |
| [ 데이터베이스 ] 6. NULL / 3 valued logic (0) | 2023.12.31 |
| [ 데이터베이스 ] 5. Subquery (0) | 2023.12.31 |



