
오래 못 할 짓 하지 않기
[ 데이터베이스 ] 11. Stored procedure 를 쓰기 힘든 이유 본문
Three-tier architecture


● Presentation : 보여지는 부분 담당
● Logic : 서비스 관련 로직 담당
● Data : 데이터 저장 및 관리 담당
당근마켓 예시로 Logic과 Data tier를 분석해보자


이렇게 Logic tier 에 기능이 들어가고 Data tier에 정보들이 담긴다
하지만 Data tier에서 사용되는 Stored procedure의 사용 목적은 비즈니스 로직 구현이다.
즉 Data tier 에 Business Logic을 넣는다는 것
Stored procedure의 장점
1) Application에 transparent하다.
: 어떤 걸 바꾸어도 크게 틀을 바꾸지 않고도 내용을 바꿀 수 있다.
= Procedure 없이 코드를 작성했을 시에는 모든 걸 바꾸고 다시 배포해야 했는데
Procedure가 있으면 Procedure body 부분만 수정하면 크게 틀을 갈아엎지 않고 수정할 수 있다.
2) Network traffic을 줄여서 응답 속도를 향상시킬 수 있다.
Logic tier와 Data tier사이에 왔다갔다 하는 것이 아니라
Data tier에서 Procedure를 부르는 것이기 때문에 traffic이 줄어든다.
3) 여러 서비스에서 재사용이 가능하다
다른 언어를 쓰고있더라도 그냥 Procedure call만 하면 된다고 함

4) 민간한 정보에 대한 접근을 제한할 수 있다.
접근은 안 되지만 Procedure로 Service Logic은 구현할 수 있게 할 수 있음
Stored procedure의 단점
1) 유지 관리 보수 비용이 커진다.
Data tier에서 Procedure를 부른다고 해도, Logic tier에서 이걸 갖다 쓸 일이 분명히 있을텐데
Logic tier에서 Procedure 를 call한다해도 이게 많아지면 Logic tier도 관리를 해야한다.
그럼 Procedure도 관리해야하고, Logic tier도 관리해야함
소스 코드 확인 > 프로시저 코드 확인
+ 버전 관리 둘 다 해줘야 한다
+ 프로시저 관련 문법도 숙지해야 함
= 유지 관리 보수 비용 ↑
2) DB 서버를 추가하는 것이 쉽지 않다. / 대신 Logic tier에 애플리케이션 서버 투입은 간단함
[ DB 서버 추가 ]

모든 Application이 하나의 DB서버를 가지고 있을 때 + Traffic이 적당할 때

모든 Application이 하나의 DB서버를 가지고 있을 때 + Traffic이 많아질 때
이런 경우에 정상적으로 작동하지 못 한다.
이 때 DB 서버를 추가한다고 해도 정상적으로 작동하지 못한다.

Application이 새로 생긴 DB에도 데이터를 주고받으려면 원래 있던 DB와 똑같은 데이터가 있어야 하는데
아무 데이터도 없기 때문이다. 따라서 원래 DB에서 데이터를 복사해와야 하는데 현재 Traffic이 넘치기 때문에 그럴 시간이 없다.
[ Application 서버 추가 ]

이 상태에서 트래픽이 많아지면

이렇게 부하가 조금씩 올라간다.
이 때 Application 서버를 늘린다면

이렇게 부하를 분산시킬 수 있다. 그럼 DB도 크게 할 게 생기는 것이 아니라 작게 여러 일이 생겨서 다루기 쉬워진다.
3) 항상 Transparent한 것이 아니다.
소스코드에 로직이 있을 때보다 손이 더 많이 갈 수 있다
ex) Procedure이름 바꾸기...등등
4) Transparent != 좋은 것
[ Transparent O ]
수정했을 때 버그가 생겼다면
고치기 전까지는 모든 Application이 잘못된 Logic으로 동작을 한다.
= 피해 범위가 커진다.
[ Transparent X ]
이 경우에는 Application 하나하나 수정하기 때문에
App 하나 수정 → 문제 생기나 확인 → App 하나 수정 ... 단계이기 때문에
문제가 생겨도 피해가 크지 않다
5) 재사용이 가능하다 != 좋은 것

재사용이 쉽다고 Procedure call이 무분별하게 많으면, DB에 과부하가 걸림
통제되지 않는 사용으로 모든 서비스에 문제가 생길 수 있다.
이런 경우에는 바로 DB로 가는 것이 아니라
그 앞 단계에서 데이터를 관리하는 서비스(application)을 만들고
다른 서비스들은 이 서비스를 통해 DB Procedure를 사용한다.

저 데이터 Service는 각각의 서비스에게 API 형태로 서비스를 제공한다.
그럼 하나의 서비스에서 많이 쓰더라도 거기만 막아버리면 된다.

6) 비즈니스 로직을 소스 코드에 두고도 응답 속도를 향상 시킬 수 있다
● 만약 순차적으로 진행할 필요 없이 동시에 실행 가능한 명령어라면?
Thread pull / Non-block IO 를 사용한다
● 만약 자주 쓰는 DB라면?
Cach 를 사용한다.
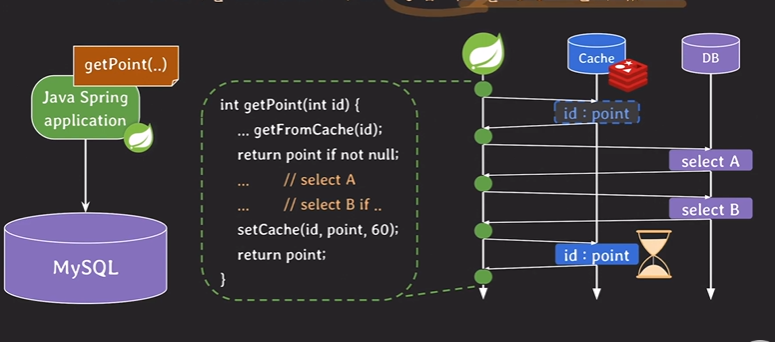
자세한 건 안 다뤘음
Cache를 사용하는 방법은 응답 속도를 향상 시키면서 DB부하까지도 줄일 수 있다.
(출처)
유튜브 쉬운코드
'3학년 1학기 > 데이터베이스(DB)' 카테고리의 다른 글
| [ 데이터베이스 ] 13. Transaction / ACID (0) | 2024.01.10 |
|---|---|
| [ 데이터베이스 ] 12. Trigger (0) | 2024.01.09 |
| [ 데이터베이스 ] 10. Stored procedure (0) | 2024.01.04 |
| [ 데이터베이스 ] 9. stored function (0) | 2024.01.04 |
| [ 데이터베이스 ] 8. 데이터 조회 - Group/ Aggregate / Order (0) | 2024.01.03 |



