
오래 못 할 짓 하지 않기
[ 컴퓨터 구조 ] 14. Control Hazard solutions 본문
Control Hazard
해결법
- Stall
→ 문제가 해결될 때까지 실행 중지 - Optimized branch processing
→ 손실을 최소화하는 방법
→ Branch 에서 Hazard가 발생하면 3CLK을 낭비하게 됨.
→ 3CLK 손실을 1CLK으로 바꿈 - Branch Predicition
→ Branch 가 될 지될지 안 될지 먼저 예측하여, Branch 될 데이터만 가져오기 - Delayed branch
→ NOP로 순서를 늦추기.
- 1번은 Data Hazard에서 다루었음

- Optimized Branch Processing
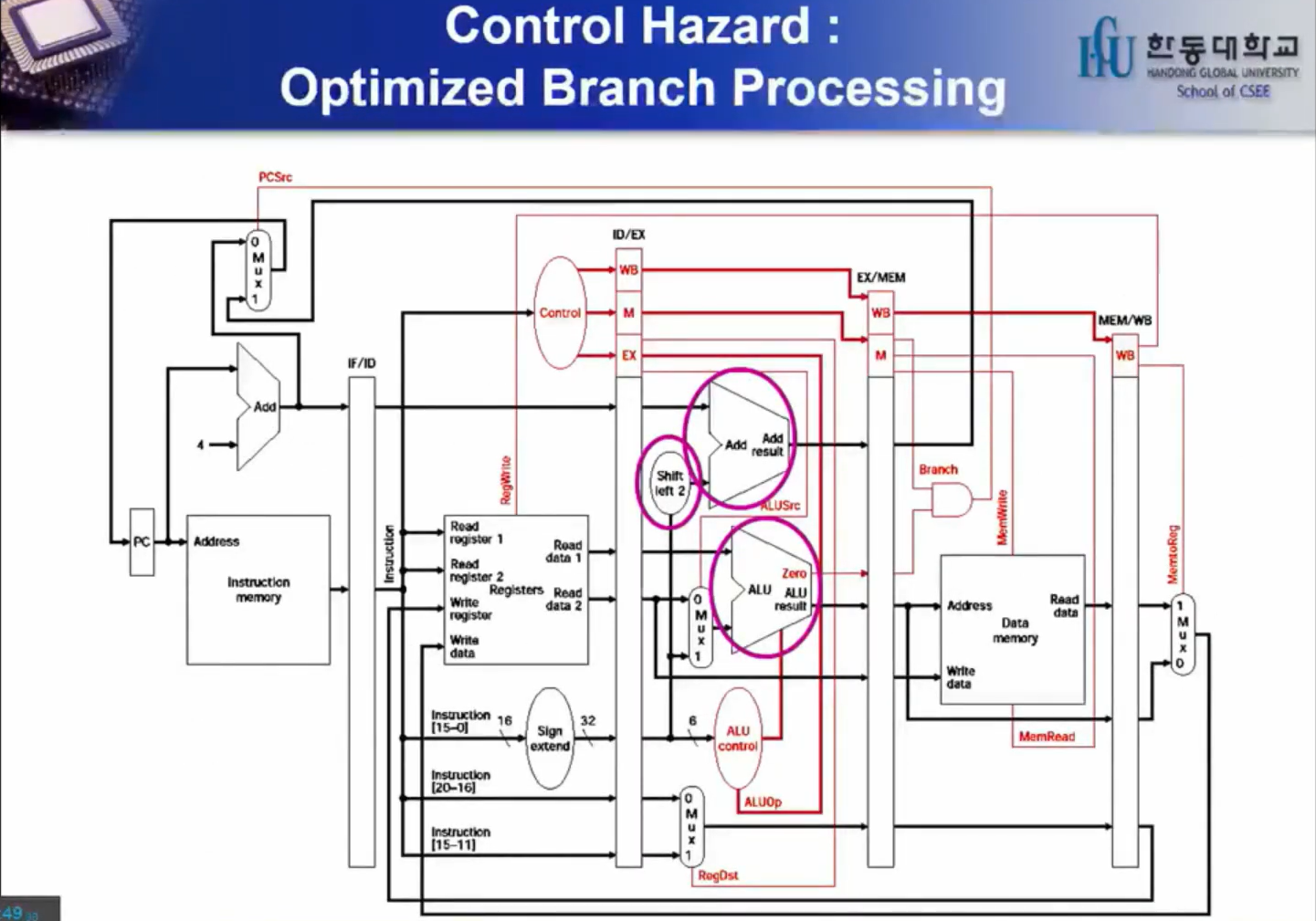
필요한 정보
1) Branch 가 일어나는지 안 일어나는지 " 미리 " 알아야 한다.
2) Target address를 " 미리 " 계산해두어야 한다.
→ Branch Execution을 ID stage까지 앞으로 당겨서 Delay를 줄인다.
( ID 까지는 가야 Branch 명령어인지 알 수 있음, 더 못 당김) , 따라서 위에 사진에서 동그라미 된 것들을 당겨보자.
▣ 우선 위에 있는 Adder와 Shift2 는 ID로 옮길 수 있다. 주소 계산하는 역할만 하니까.
하지만, 그 아래에 있는 Adder는 역할이 더 많기 때문에, 얘까지 ID단으로 옮겨버리면 4 CLK이 되고
ID단에는 더 많은 것들이 들어오게 되어서 CLK 시간이 일정하지 않아진다.
대신, 그 역할을 하는 게이트를 하나 만들면 된다. 같으면 Branch이므로, 같은지 아닌지 확인하는 건 ALU Subtract로 했는데 그냥 XOR를 사용하면 비교가 가능하다. 이렇게 Datapath를 수정하면, 아래와 같다.

왼쪽 가장 위 Control 신호를 보자.
IF Flush 역할 : IF Pipeline register에 NOP를 삽입하여 Clear 시켜준다.
위 사진과 설명들처럼 ID단으로 옮기고 IF Flush를 사용하면 3 CLK 낭비할 것을 1 CLK으로 줄일 수 있다.
Branch Prediction
이제부터 나오는 것들은 그 마저도 손해보지 않는 방법이다.

▣ 일단 가장 간단한 방법은 [ Branch 가 일어나지 않는다고 가정 ] 하고 설계하는 것
그리고 그 가정이 틀렸을 때는 Bubble ( = NOP = Idle ) 를 삽입하여 IF단에 있는 명령어를 지우고, Branch에 신경을 쓴 다.
이럴 때, Branch 가 일어나지 않았을 경우에는 이익, Branch가 일어나도 본전임.
예측 ( 가정) 하는 법 3개
Static Branch Prediction
1) Branch가 발생 X를 Default로 (우리가 위에서 한 방법)
2) Branch가 발생 O를 Default로
3) OP code에 따라
1) beq : Branch가 발생 X를 Default로
2) bne : Branch가 발생 O를 Default로
Dynamic Branch Prediction
- Branch Prediction Buffer / Branch Histroy Table
앞 명령어(history) 에서 Branch가 일어났다 ? → 이번 명령어에서도 Branch가 일어날 수 있으니 그거에 맞게 준비.

앞 놈이 어떻게 했는지 한 반자 늦게 따라가는 거임.
단점 : Branch 했다 > 안 했다 > 했다 ... 이렇게 하면 극비효율

이전 Prediction의 단점을 (그나마) 보완함.
1번 더 기회를 줌!
▣ 초기 상태 : Branch 하는 거로 맞춰져 있음
→ Branch 안 해 ? > 그래도 한 번 기회 줄게, 한 번만 더 안 하면 바꾼다 > 안 함 > Branch 안 하는 거로 맞춤
ㄴ > 함 > Branch 하는 거로 맞춤
Delayed Branch

→ Optimized Branch Processing을 사용하면서, Hazard detection unit을 사용하지 않는 방법.

명령어의 순서가 BEQ → ADD → LW라고 해보자
BEQ에서 Branch가 일어나면 작업을 하는 도중에, 즉, Branch가 완료되기 전에 ADD가 실행된다.
그런 다음에 Branch가 완료되기 때문에 그 뒤로 한 칸씩 밀림.
해당 방법은 그 1CLK Delay를 감수하면서 실행하겠다 이 말이다~
Branch 명령어 다음에 오는 slot = Delay slot
Delay slot에는 Branch를 할 때나 하지 않을 때나 실행되는 명령어들이 들어옴

(위) Branch가 일어나지 않았을 때는 잘 진행된다.
(아래) Branch가 일어났을 경우에는, Branch ( i번째 ) 명령어가 먼저 실행됨
→ 그다음 i+1 번째 명령어도 실행됨 (Branch prediction에서는 이걸 NOP로 바꿈)
→ i+2번째 자리에 Branch target이 되면서 그 뒤로 target instrcutions이 실행.
( BEQ = 몇 칸 뒤에 있는 명령어로 가자! )

3가지 예시:
- R2가 Branch Target이 되는데, ADD가 Branch 다음에 실행되더라도 크게 문제가 없기 때문에
자리를 Branch 명령어 아래에 두어도 된다. - 2번째 위 예시는 프로그래밍 흐름으로 분석해 보자. 우선 위쪽일 때는
Sub 먼저 계산 → Add 계산 → If 문 거쳐서 참이면 branch하여 다시 Sub 계산 → Add 계산
= Sub 2번, Add 2번 계산됨
아래 예시로 보면 Add 계산 → If문 읽는 거랑 Sub계산 같이 됨 → Add 계산 → If문 읽는 거랑 Sub계산 같이 됨
= Sub 2번, Add 2번 계산됨
Dependency가 없어서 가능! - Target → Delay slot 으로 옮겼을 때
Branch가 되든 안 되든 어차피 실행되는 명령어는, Target에서 Delay slot으로 옮겨도 결과가 같다.
Branch 되면 Sub으로 가고, 안 되어도 그 위에 다 거친 다음에 Sub으로 온다. 어차피 올 거 Branch if 읽을 때 같이 실행되게 함.
요약 : 7_2 번 강의 34:40

참고 : https://hi-guten-tag.tistory.com/267
출처 : 한동대 SW중심대학
'2학년 2학기 > 컴퓨터 구조' 카테고리의 다른 글
| [ 컴퓨터 구조 ] 16. (Hazard) Flushing logic (0) | 2023.07.11 |
|---|---|
| [ 컴퓨터 구조 ] 15. (Hazard) Data Forwarding logic (0) | 2023.07.10 |
| [ 컴퓨터 구조 ] 13. Data Hazard (0) | 2023.07.07 |
| [ 컴퓨터 구조 ] 12. Pipeline 제어부 (Control) (0) | 2023.07.07 |
| [ 컴퓨터 구조 ] 11. Pipeline DataPath (0) | 2023.07.06 |



