

오래 못 할 짓 하지 않기
[ 컴퓨터 구조 ] 15. Datapath - Single/Multi CLK Cycle (강의 multi 2) 본문
[ 컴퓨터 구조 ] 15. Datapath - Single/Multi CLK Cycle (강의 multi 2)
쫑알bot 2023. 10. 29. 15:33( Single datapath에 있는 명령어들이 어떤 흐름으로 돌아가는지 파악 해야함 → pdf 4-1 49페이지부터! )
Single CLK cycle
- Single CLK cycle은 모든 연산이 한 번에 돌아가야한다.
- 따라서 모든 것이 한 번에 될 때까지 기다려야함.
→ ALU가 여러 개가 있으므로 각각에 연산이 될 때까지 기다려야함.
- CLK time은 Datapath 중에 가장 긴 놈으로 맞추어서 작동함.
주로 오래 걸리는 건 아래와 같은 것을 수행할 때다.

이것과 관련해서 생각해보면 위에 있는 3개의 연산을 다하는 LW가 가장 오래 걸린다.
이러한 점이 Single CLK Cycle의 문제점이라고 할 수 있다.
- 복잡한 Inst일 땐 어떡할거냐 / 명령어마다 필요한 시간이 다름.
- 낭비되는 Chip area가 너무 많다 ( = ALU가 너무 많다. )
→ 해결법 : 짧게 끝낼 수 있는 명령어는 짧게 = Multicycle datapath
Multicycle datapath
Multicycle datapath의 가장 큰 특징은 [ 유닛의 재사용 ] 이다.
- ALU : [ PC값 +4 ] , [ branch ] , [ Address 계산 ] 하는 용도로 3개를 쓰고 있었는데
MultiCycle에서는 하나로 합친다. - Memory : [ Instruction ] , [ Data ] 를 가져오는 용도로 2개의 Memory단을 만들었었는데
MultiCycle에서는 하나로 합친다.
그냥 Moore Machine 으로 구현한다 정도만 알면 됨
Multicycle datapath 에 대한 알고리즘은 간단하다
- 한 Inst를 여러 Steps으로 나눈다.
- 각 Step이 한 Clock Cycle을 차지한다.
1개 명령어 = #개의 작업 → #개의 Clk으로 나눈다.
Clock당 시간은 가장 오래 걸리는 작업에 맞춘다.
Singlecycle datapath VS Multicycle datapath(중요!!)
1. 1개의 메모리
2. 1개의 ALU
3. 앞 step에서 연산한 결과를 넘겨주는 Register
4. MUX가 더 필요함 ( ex. 메모리에서 data를 가져오는지 inst를 가져오는지 정하기 위함 )

Five Execution Steps
1. Instruction Fetch
: 명령어 가져오기
2. Instruction Decode and Register Fetch
: 가져온 명령어 해석 → 레지스터 값 읽기
레지스터 값 읽기 = 예를 들어 add $t1 , $t2, $r0 이렇게 있으면 t2랑 r0 레지스터 값 읽는 거
3. Execution( R-type ), Memory Address Computation ( LW / SW ), or Branch Completion
: Inst type 에 따라서 3개 중에 뭘 할지 정한다.
* Branch 명령어면 여기에서 끝남.
4. Memory Access( LW / SW ) or R-type instruction completion
: 메모리에 가서 작업을 한다 / R타입 연산 완료
* R-Type 명령어 or SW면 여기에서 끝남.
5. Write-back step
: LW만 한다.
결론적으로 명령어 타입에 따른 명령어 개수를 보면
Branch Inst : 3
R type / SW : 4
Lw : 5
각 단계별 분석
1. Instruction Fetch
: PC값을 이용해서 Mem에 있는 Instruction을 Register에 넣는다.
> PC값을 4 증가시킨다.
IR <= Memory[PC];
PC <= PC + 4;
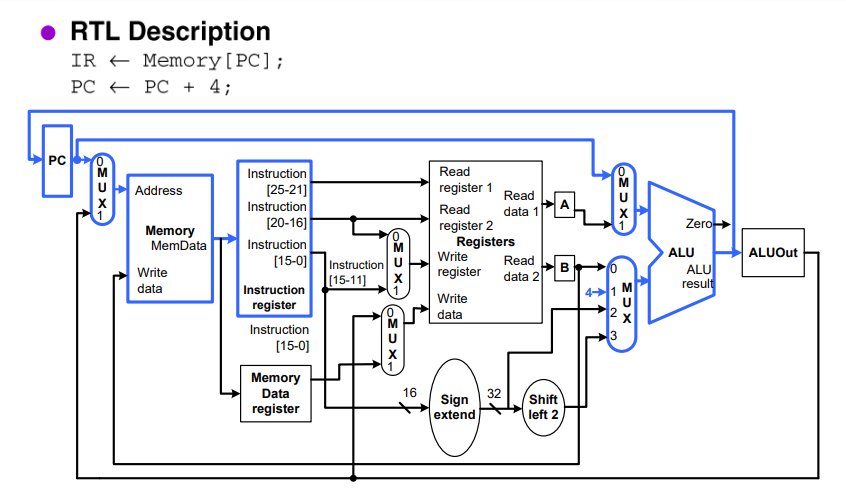
2. Instruction Decode and Register Fetch
- 명령어에 있는 rs, rt Register값을 읽는다.
- 혹시나 하니까 Branch주소를 계산한다. ( 아직 R / I / J 에 따른 control을 못 만들어서 그럼 )
>> 쓰진 않을거긴 한데 뭐 해서 안 좋을 거 없어서 한다고 함
A <= Reg[IR[25-21]];
B <= Reg[IR[20-16]];
ALUOut <= PC + (sign-extend(IR[15-0]) << 2);
3. Execution( R-type ), Memory Address Computation ( LW / SW ), or Branch Completion
- 명령어 타입에 따라 명령어를 수행한다.
• Memory Reference : ALUOut = A + sign-extend(IR[15-0]); // I타입 : 메모리 주소 계산
• R-type : ALUOut = A op B; // R타입 : opcode에 맞는 연산
• Branch : if (A==B) PC = ALUOut; // Branch 관련 명령어 : Branch 조건 연산
이런 명령어는 여기까지만 하고 끝!

4. Memory Access( LW / SW ) or R-type instruction completion
• Loads and stores access memory
MDR = Memory[ALUOut]; // LW : 계산된 주소의 메모리 값을 Register로 가져오는 거
or
Memory[ALUOut] = B; // SW : Regitser의 값을 계산된 메모리에 저장하는 것 이거 하고 끝
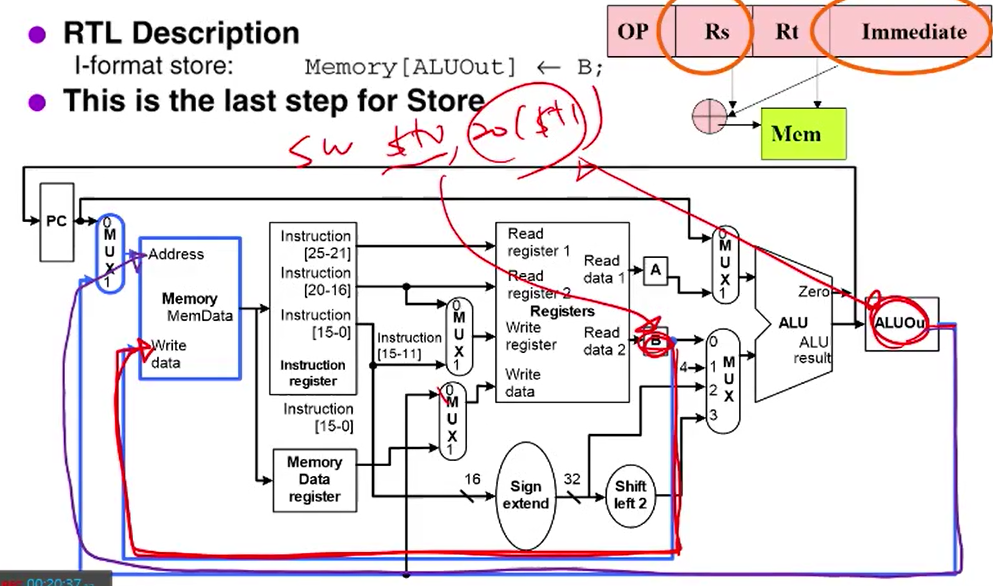
[ SW ]
B에서는 rs값= 저장할 값을 가져오고
ALUOut에서 저장할 주소를 가져온당~
[ R-type instructions completion ]
Reg[IR[15-11]] <= ALUOut; // 계산한 값 rd에 넣기
5. Write-back step
• Reg[IR[20-16]] = MDR;
// 메모리에서 가져온 걸 레지스터에 넣었고,
그걸 다시 우리가 원했던 레지스터에 넣는다 ( 휴게소 정도로 생각하면 될 것 같다. )
예제)

Single : 어떤 명령어든지에 관계없이 한 명령어는 90ns가 걸린다.
( 10 + 10 + 20 + 10 ) * 90 = 4500ns
Multi : 각 명령어마다 소요되는 step의 수가 다르다. 따라서 그에 따른 계산을 따로 해야한다.
- Branch Inst : 3 개
- R type / SW : 4 개
- Lw : 5 개
( 10*5 + 10*4 + 20*4 + 10*3 ) * 20 = 4000ns
(출처)
한동대학교 용환기교수님 - 컴퓨터구조
'2학년 2학기 > 컴퓨터 구조' 카테고리의 다른 글
| [ 컴퓨터 구조 ] 17. Datapath - Pipeline with Control signals (0) | 2023.11.06 |
|---|---|
| [ 컴퓨터 구조 ] 16. Datapath - Pipeline (1) | 2023.11.02 |
| [ 컴퓨터 구조 ] 14. Datapath - Single Path (0) | 2023.10.24 |
| [ 컴퓨터 구조 ] 13. Floating Point number 2 (0) | 2023.10.15 |
| [ 컴퓨터 구조 ] 문제풀기 2 (0) | 2023.10.12 |



