
오래 못 할 짓 하지 않기
[ 컴퓨터 구조 ] 16. Datapath - Pipeline 본문
Pipeline
● 목적 : 전체 작업을 하는 데 걸리는 시간을 줄임 → [ CPU의 성능 향상 ]
● 특징 : 여러 개의 명령어를 동시에 실행한다

single : 하나의 일은 무조건 @시간 만큼 해라
Multi : 빨리 끝나면 바로 그 다음 거 해라
Processing을 구조를 그림으로 보면
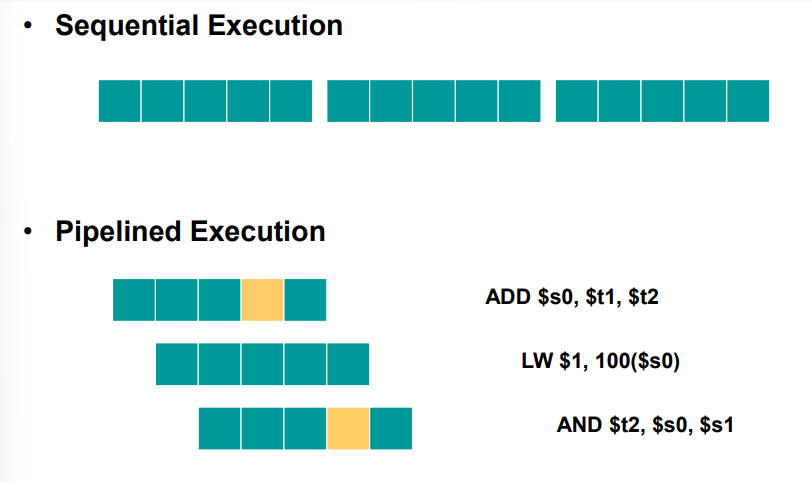
[ Sequential ]

[ Pipeline ]

직관적인 예시로는
노래방에서 차례대로 노래 부르는 거 / 돌림노래 부르는 거 차이라고 생각하면 된다.
Pipeline 특
- 하나의 작업이 빨리 끝나게 도와주는 게 아니라
전체 작업을 빨리 끝내는 거다 (퇴근 일찍 할 수 있게 해주는 거임) - 다른 영역의 일들을 같은 시간대에 작업한다
- 시간이 줄어들 확률 = Pipe로 나눈 영역의 개수
- Pipeline으로 나눈 것들 중에서 가장 오래 걸리는 영역의 시간으로 맞춘다.
→ 그래서 빨리 끝나는 것들은 시간 Waste가 있음.

N개의 job , 하나의 job은 T초가 걸린다.
a) Pipeline X
→ Ts = n*T
( 한 개의 명령어당 T가 걸리고, n개의 명령어를 실행하면 n*T )
b) Pipeline O => k개의 stage로 나눠놨다 ( 동시에 k개의 작업 가능 ) , 각 stage는 T/k 초가 걸린다.
→ Tp = (n+k-1) * T/k
한 명령어를 k개로 쪼개면 한 [ work = 작업= stage ]당 걸리는 시간 = T/k
=> 첫 번째 inst 가 끝나는 건 k번째 CLK일 때( k개로 쪼갰으니까)
두 번째 inst 가 끝나는 건 k+1번째 CLK일 때
... n번째 inst가 끝나는 건 (k+(n-1))번째 CLK일 때 .
그럼 지속시간은 (k+n-1) 이고 이걸 * T/k와 곱해준다. )
+ speedUp 은 = Sp = Ts / Tp = (n*k) / (n+k-1)
n이 무한대로 가면 극한으로 계산해서 k(/1) 가 된다.
예제)

Pipeline Execution
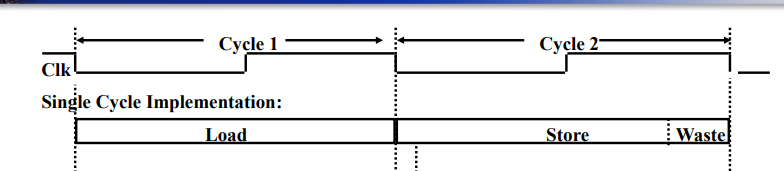
[ Single CLK 이 작업하는 방식 ]
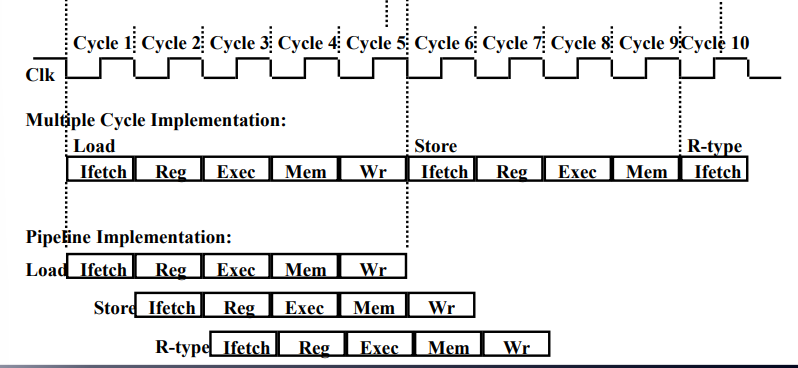
[ Multi CLK (+Pipeline) 이 작업하는 방식 ]
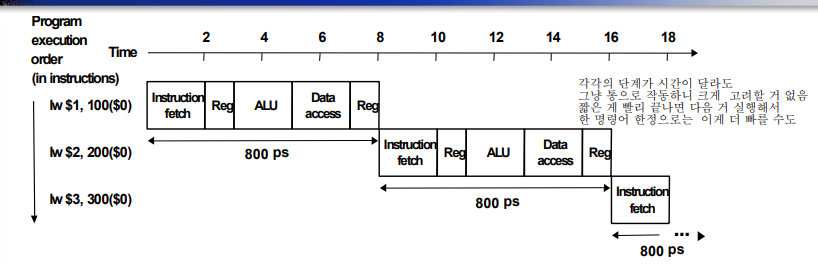
실행 시간의 차이가 얼마나 있는지 LW명령어로 확인해보자
Pipeline X
1) 각각의 단계가 시간이 달라도 그냥 통으로 작동하니 크게 고려할 거 없음
2) 간단한 step이 빨리 끝나면, 다음 step으로 바로 가기 때문에
하나의 명령어 한정으로는 이게 더 빠를 수도 있음 (waste가 없기 때문)
Pipeline O
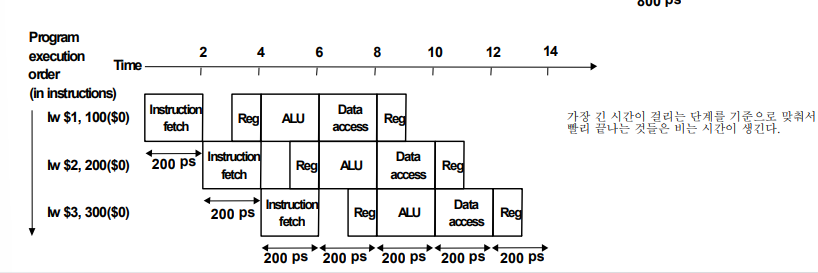
가장 긴 시간이 걸리는 단계를 기준으로 맞춰서
빨리 끝나는 것들은 비는 시간이 생긴다.
결론: Sepedup = 2400 ps / 1400 ps = 1.7 쯤
Pipeline을 쉽게 할 수 있는 이유!
● all instructions are the same length
→ Simplicity favors Regularity
어떤 건 32bits고, 어떤 건 48bits이면 뭐가 제대로 안 됨
● just a few instruction formats
→ 사용하는 명령어가 주로 8~9개로 정해져있기 때문에 뭐가 와도 준비되어 있음
● memory operands appear only in loads and stores
→ Mem 접근은 LW / SW에만 있기 때문에 그래도 할만하다. 자주 안 가도 돼서
Mem 대신 레지스터를 사용하기 때문에 Mem access가 많지 않다.
Pipeline을 어렵게 만드는 요소
● Structural hazards : 그냥 구조적인 문제라고 하심
● Data hazards : 명령어에서 쓰이는 Data들끼리 서로 Dependency가 있을 때 생기는 문제
● Control hazards : Branch 하면 기껏 들고왔던 다음 명령어들이 쓰이지 않게 되어 생기는 문제
(출처)
한동대학교 용환기교수님 - 컴퓨터구조
'2학년 2학기 > 컴퓨터 구조' 카테고리의 다른 글
| [ 컴퓨터 구조 ] 18. Hazard (0) | 2023.11.06 |
|---|---|
| [ 컴퓨터 구조 ] 17. Datapath - Pipeline with Control signals (0) | 2023.11.06 |
| [ 컴퓨터 구조 ] 15. Datapath - Single/Multi CLK Cycle (강의 multi 2) (1) | 2023.10.29 |
| [ 컴퓨터 구조 ] 14. Datapath - Single Path (0) | 2023.10.24 |
| [ 컴퓨터 구조 ] 13. Floating Point number 2 (0) | 2023.10.15 |



