
오래 못 할 짓 하지 않기
컴구 기말 본문
챕터 5
- DISK의 용량 / CPU의 속도를 가져오려고
Cache를 만들었다.
- (코드 주고) > 어떨 때 뭐가 유리함?
- Temporal Locality: 변수 하나 만들어서 그거 계속 돌려먹을 때
ex) a= b+1;
d = 4*a +c;
- Spatial Locality : 배열 사용할 때
ex) for( int i=0; i<10000 ; i++){
a[i] = i;
} - 하나의 Block에 있는 거
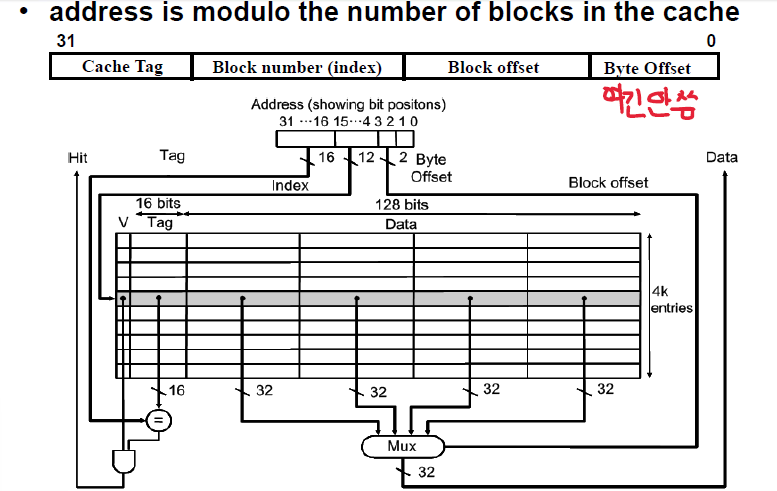
Valid bit
Tag
Data
* 참고로 Tag 비트 수는 유동적이므로 계산하는 것도 할 줄 알아야한다

- ● Read Misses : 원하는 거 없음
→ CPU stall
→ Mem에서 필요한 데이터가 있는 block fetch
→ cache로 그 데이터를 옮긴다.
→ 다시 시작
- Write through ( Dirty bit 필요 X )
- 장점 : Miss인 상황에 작업이 빠르다.
이유 : cache에 있는 값과 memory에 있는 값이 일치하므로,
새로운 값을 가져와도 다시 업데이트 할 필요가 없다.( = 다시 돌려주면서 업데이트를 할 필요 X )
- 단점 : Cache가 업데이트 될 때마다 memory에 접근해야 하므로, 시간이 더 걸린다.
- Write back ( Dirty bit 필요 )
- 장점 : 메모리에 쓰는 걸 반복하지 않아도 된다.
- 단점 : 굳이 꼽자면 Dirty bit를 보고 Miss가 나면 Update를 해야한다.
Dirty bit
- 특징 : Dirty or clean을 확인한다.
- 용도 : 교체될 때 Update해야하는지 굳이 안 해도 되는지 판단하기 위함
이제 Performance측면으로 분석해보자
한 Block에 여러 word를 가져온다고 가정.

[ Miss 상황 ]
Mem → Cache → CPU 시간을 기다려야 한다.
Performance를 줄이려면?
1. Miss 확률 ↓ ( 그럼 많이 가져와야하는데, Miss penalty가 커지고, spatial locality 저하 유발 )
2. Miss Penalty ↓
Placements
1) Direct : Tag로 자신에게 맞는 칸에 mapped된다
Block(index)로 들어가서 Tag에 맞게 Mapped된다.
2) Fully associative : 빈칸이 있으면 그냥 아무렇게나 들어간다.
특징 : 아무 곳에나 저장 가능
= 정보 찾으려면 오래 걸림 = 별로 유용하지 않음
> parallel하게 동시에 [ 찾으려는 데이터의 tag ]와 [ 주소를 나타내는 tag ] 여러 개 비교할 수 있도록 만들어야 한다!

3) Set associative : 위 2개가 섞인 느낌이다. Set는 태그로 들어가고, 그 안에서는 맘대로 들어감
set는 정해줄게 그 안에는 너가 알아서 들어가
● 장점 : Associative set의 개수가 늘어나면 miss날 확률이 줄어든다.
● 단점 : hit인지 확인하는 데 오래걸림.
ex) tag로 들어가서 다 찾아보고, 그 다음 tag에서 다 찾아보고...
* Replacement 방식에 따라 새로 들어오는 데이터가 어느 자리에 갈지 정해짐.
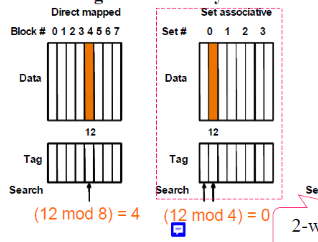
왼쪽이 Direct mapped / 오른쪽이 set associative
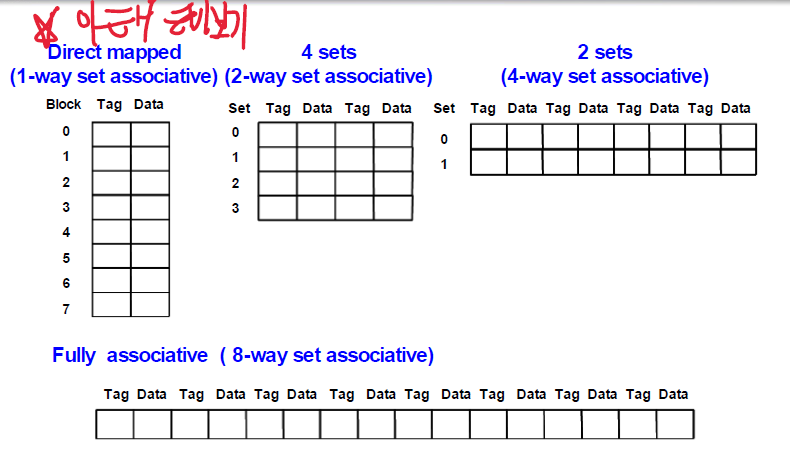
다 이렇게 표현 가능
Replacements
miss가 난 경우에 Fully나 set associative cache에서는 어떻게 해야할까 에 대한 대답
- 랜덤 : 새로운 애 들어와야 하니까 아무나 나가
- 선입선출 ( First In, First Out ) (사용된 시점에 집중)
- 가장 오래동안 있었던 애를 내보냄
- 이를 위해서는 언제 왔는지 알기 위한 Time Stamp 기능이 필요함
- Queue로 구현 가능
*문제점 : 걔가 앞으로 가장 많이 쓰일 데이터라면?? - Least Recently Used (LRU) (사용된 시점에 집중)
- 가장 최근에 사용하지 않은 것
= 지금 기준 제일 옛날에 "사용" 한 것을 내보냄
- 쓰일 때마다 Time Stamp 필요하다 = Overhead가 심하다.
FIFO와 공통점 : Time Stamp를 참고하여 내보낸다
차이점 : Time Stamp가 찍히는 시점이 다르다 ( 들어왔을 때 vs 사용될 때 ) - Least Frequently Used (LFU) (사용된 횟수에 집중)
- 가장 적게 쓰인(= reference된 ) 것
Reference될 때마다 count를 하고, Miss이고 데이터가 다 찼을 때 count값이 가장 적은 데이터를 내보냄
빈틈 : 들어온지 얼마 안 된 데이터는 상대적으로 count가 적을 수 밖에 없어서 얘네가 쫓겨날 수도 있음
'2학년 2학기 > 컴퓨터 구조' 카테고리의 다른 글
| [ 컴퓨터 구조 ] 24. File I/O (0) | 2023.12.02 |
|---|---|
| [ 컴퓨터 구조 ] 23. Virtual memory (0) | 2023.11.27 |
| [ 컴퓨터 구조 ] 22. Cache performance (0) | 2023.11.26 |
| [ 컴퓨터 구조 ] 21. Direct ( cache ) (0) | 2023.11.20 |
| [ 컴퓨터 구조 ] 12주차 makeup 문제 (0) | 2023.11.16 |



